
Migrated from eDJGroupInc.com. Author: Greg Buckles. Published: 2014-09-29 20:00:00Format, images and links may no longer function correctly.
It is the middle of discovery interviews and you are going though your interview form checking off data sources with a key witness. You get to the final question, “Are there any other data sources, communication or collaboration systems that might be relevant to this matter?” You hold your breath, hoping that you can avoid collection of texts, Lync or other esoteric data sources that will blow up your processing and review budget estimates. “Well, the team started using Yammer back with Microsoft bought it. I think that we have a topic on that contract and I know that we have had several conversations about those pricing spreadsheets.” Ugh. Yammer? You take notes, get login credentials and the admins name. You have no idea what the system contains, how it is accessed or what you will get when you shoot the export request over to the Yammer administrator. Here is what it might look like…
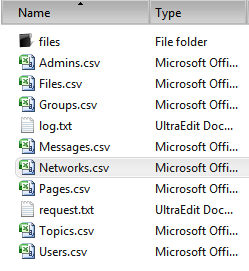
You are going to receive a giant zip file with EVERYTHING in Yammer. The only filter you can use is a ‘Since Date’ limit in case your scope is limited to very recent events. Since eDiscovery usually involves a cut off date (everything BEFORE MM/DD/YYYY), this is pretty useless unless you have been regularly ‘archiving’ chronological chunks of Yammer content, which opens a whole host of issues. The zip file will have a bunch of delimited .CSV files matching the Yammer tables and a one or two folders with all of the attached files (renamed with the Yammer ID and their regular file extension) or wiki style pages. What you probably want will be in a couple files:
- Files.csv –basic relationship between the FileID (name on the file) and the context
- Messages.csv – ID, thread, sender, body, attachments and dates
- There is a ‘Participants’ and GroupID field, but I have found messages with no recipient information retained in early testing – more info after I dig into it
- Pages.csv-metadata for user created Notes or Pages (same thing as far as I can tell). Pages are saved in .HTML format. You can attach uploaded files to pages, but your links will be broken on export
- Users.csv – The Messages.csv and Pages.csv have some name fields expanded, but some will require cross reference to fully populate information
All of this looks pretty straight forward for any experienced Litigation Support analyst to either manually filter for specific custodians, date ranges and even search terms in messages, pages or files (with local search engine like X1). However, the fielded metadata is pretty sparse compared to real email, SharePoint or network file shares. You are probably going to have to load these tables to SQL or MS Access, create the relationship joins and export a couple of fully populated load files. A sharp SharePoint admin in one of our clients already figured out how to do a template with these relationships in SharePoint. Once you run through a couple of discovery scope scenarios with group discussions, pages pointing at linked files that have already been sent as messages and more, this could become a major headache to extract for review. Until Yammer supports native granular search and export functionality, the field is wide open for eDiscovery collection software to build fast connectors and fill this gap. So have you had to collect from Yammer or other collaboration software? Take my short poll on Collaboration Platform eDiscovery (if you tried a couple weeks ago, we found and fixed the link bug).
Greg Buckles can be reached at Greg@eDJGroupInc.com for offline comment, questions or consulting. His active research topics include analytics, mobile device discovery, the discovery impact of the cloud, Microsoft’s 2013 eDiscovery Center and multi-matter discovery. Recent consulting engagements include managing preservation during enterprise migrations, legacy tape eliminations, retention enablement and many more.